本文主要介绍堆与栈,以及他们在JavaScript语言底层的应用。
栈
- 定义
- 后进者先出,先进者后出,简称 后进先出(LIFO),这就是典型的栈结构。
- 在栈里,新元素都靠近栈顶,旧元素都接近栈底。
- 从栈的操作特性来看,是一种 操作受限的线性表,只允许在一端插入和删除数据。
- 不包含任何元素的栈称为空栈。
栈被用在编程语言的编译器和内存中保存变量、方法调用等,比如函数的调用栈、前端路由等。

堆
定义
- 堆数据结构是一种树状结构
- 它的存取数据的方式,与书架相似:我们不关心书的放置顺序是怎样的,只需知道书的名字就可以取出我们想要的书
堆与栈比较
- 栈,线性结构,后进先出,便于管理。
- 堆,非线性结构,杂乱无章,方便存储和开辟内存空间。
- 堆是动态分配内存,内存大小不一,不会自动释放。
- 栈是自动分配相对固定大小的内存空间,并由系统自动释放。
JS在浏览器上的运行机制
我们知道 JavaScript 是单线程的,所谓单线程,是指在 JavaScript 引擎中负责解释和执行 JavaScript 代码的线程唯一,同一时间上只能执行一件任务。
为什么是单线程?这是因为 JavaScript 可以修改 DOM 结构,如果 JavaScript 引擎线程不是单线程的,那么可以同时执行多段 JavaScript,如果这多段 JavaScript 都修改 DOM,那么就会出现 DOM 冲突。
为了避免 DOM 渲染的冲突,可以采用单线程或者死锁,JavaScript 采用了单线程方案。
但单线程有一个问题:如果任务队列里有一个任务耗时很长,导致这个任务后面的任务一直排队等待,就会发生页面卡死,严重影响用户体验。
为了解决这个问题,JavaScript 将任务的执行模式分为两种:同步和异步。
同步
1
2
3// 同步任务
let a = 1
console.log(a) // 1异步
1
2
3
4// 异步任务
setTimeout(() => {
console.log(1)
}, 1000)
同步任务都在主线程( JavaScript 引擎线程)上执行,会形成一个 调用栈(执行栈);
除了主线程外,还有一个任务队列(也称消息队列),用于管理异步任务的 事件回调 ,在 调用栈 的任务执行完毕之后,系统会检查任务队列,看是否有可以执行的异步任务。
注意:任务队列存放的是异步任务的事件回调
例如上例:
1 | setTimeout(() => { |
在执行这段代码时,并不会立刻打印 ,只有定时结束后(1s)才打印。 setTimeout 本身是同步执行的,放入任务队列的是它的回调函数。
下面我们重点看一下主线程上的调用栈。
调用栈
调用栈是用来管理函数调用关系的一种栈结构 。
下面通过一个简单例子说明调用栈如何管理函数调用关系:
1 | var a = 1 |
在执行这段代码之前,JavaScript 引擎会先创建一个全局执行上下文,包含所有已声明的函数与变量:
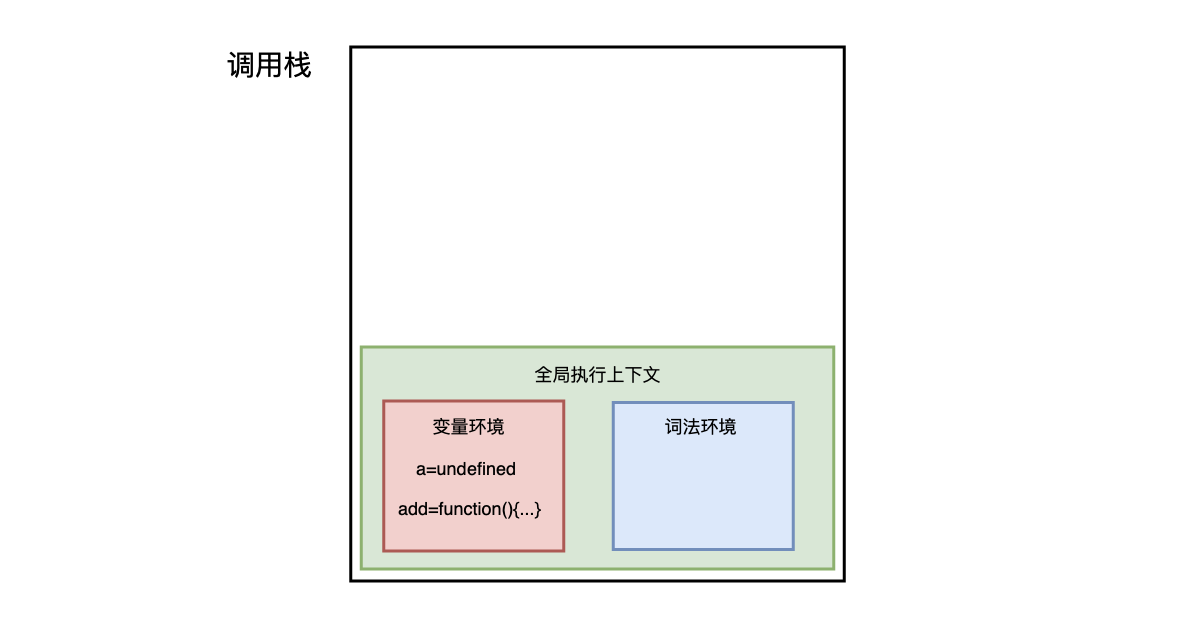
从图中可以看出,代码中的全局变量 a 及函数 add 保存在变量环境中。
执行上下文准备好后,开始执行全局代码,首先执行 a = 1 的赋值操作,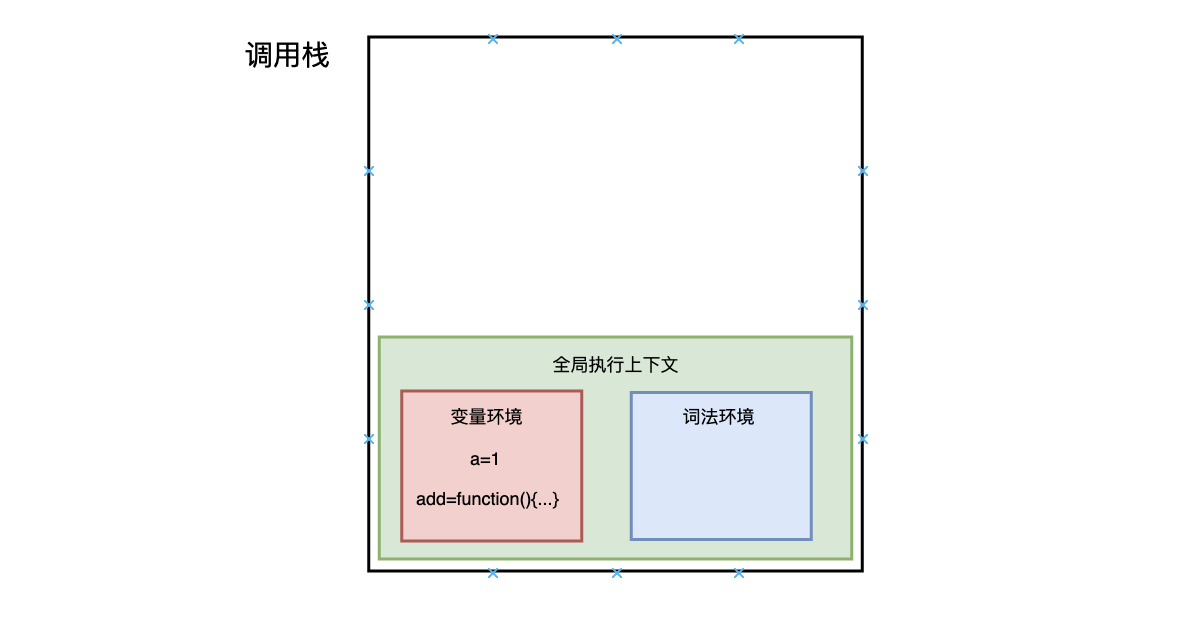
赋值完成后 a 的值由 undefined 变为 1,然后执行 add 函数,JavaScript 判断出这是一个函数调用,然后执行以下操作:
首先,从全局执行上下文中,取出 add 函数代码
其次,对 add 函数的这段代码进行编译,并创建该函数的执行上下文和可执行代码,并将执行上下文压入栈中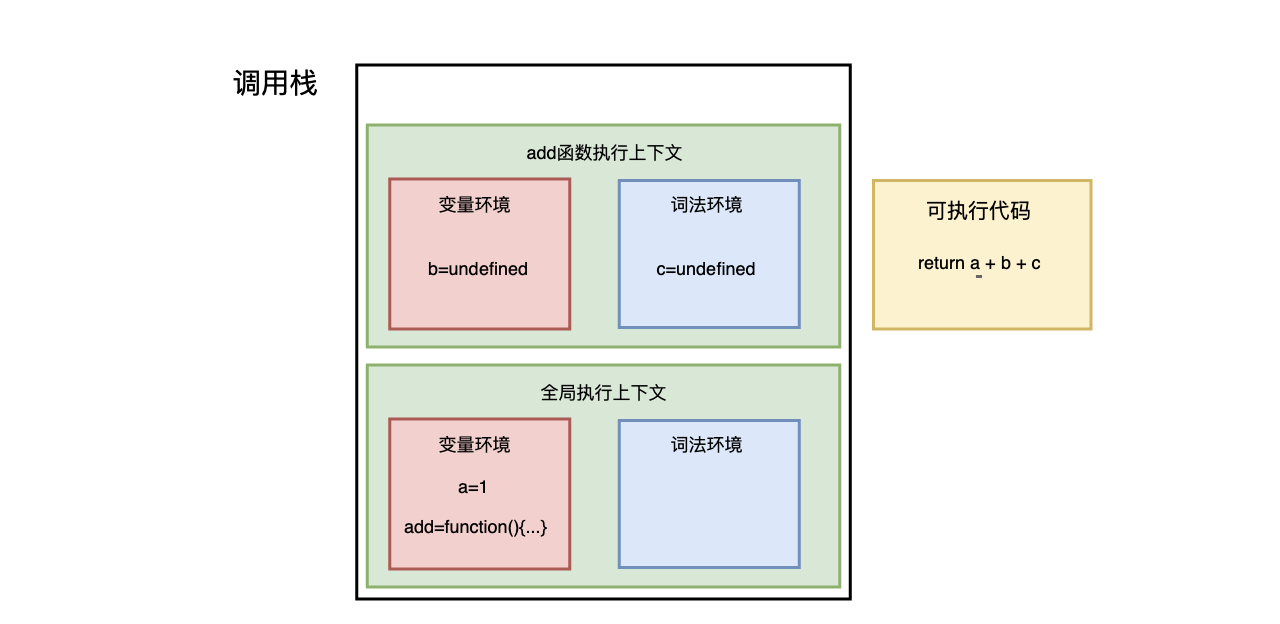
然后,执行代码,返回结果,并将 add 的执行上下文也会从栈顶部弹出,此时调用栈中就只剩下全局上下文了。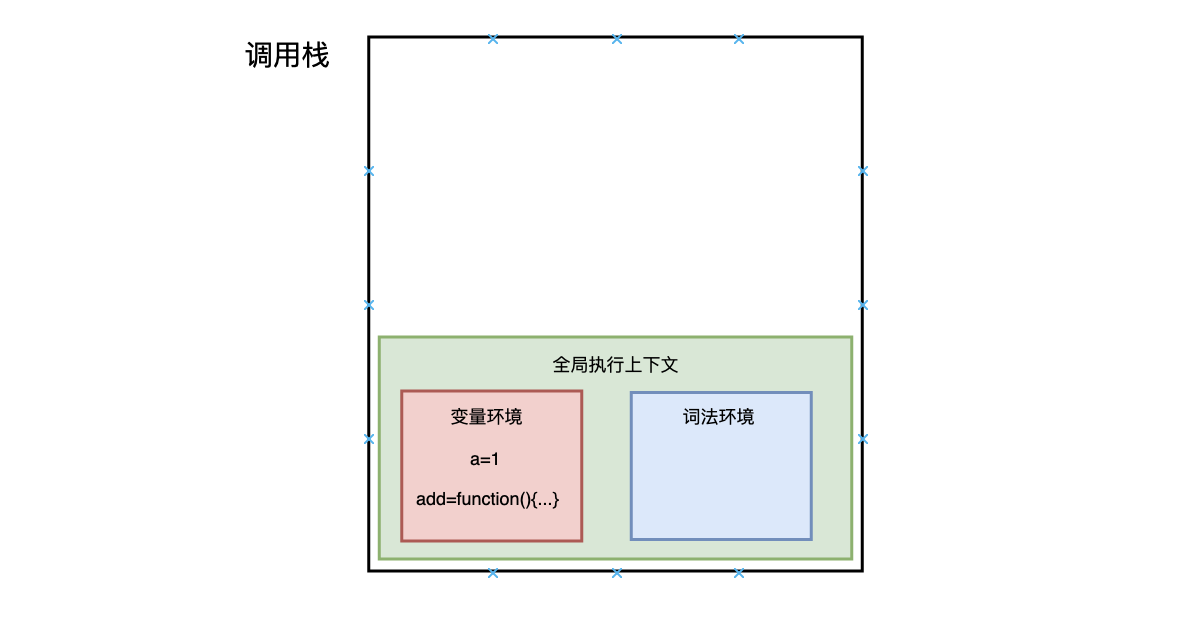
至此,整个函数调用执行结束了。
所以说,调用栈是 JavaScript 用来管理函数执行上下文的一种数据结构,它记录了当前函数执行的位置,哪个函数正在被执行。 如果我们执行一个函数,就会为函数创建执行上下文并放入栈顶。 如果我们从函数返回,就将它的执行上下文从栈顶弹出。 也可以说调用栈是用来管理这种执行上下文的栈,或称执行上下文栈(执行栈)。
了解了什么是调用栈,就能方便的理解栈溢出了,因为调用栈是一个栈结构,它有容量上限,当入栈的上下文过多的时候,它就会报栈溢出。
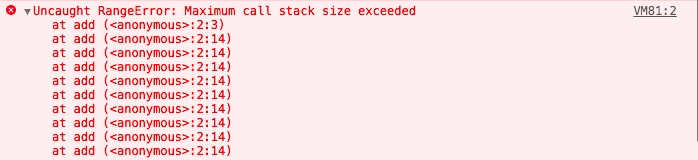
可以通过
console.trace()来查看函数的调用栈路径
栈内存与堆内存
JavaScript 中的变量分为基本类型和引用类型。
基本类型是保存在栈内存中的简单数据段,它们的值都有固定的大小,通过按值访问,并由系统自动分配和自动释放。 这样带来的好处就是,内存可以及时得到回收,相对于堆来说,更加容易管理内存空间。 JavaScript 中的 Boolean、Null、Undefined、Number、String、Symbol 都是基本类型。
引用类型(如对象、数组、函数等)是保存在堆内存中的对象,值大小不固定,栈内存中存放的该对象的访问地址指向堆内存中的对象,JavaScript 不允许直接访问堆内存中的位置,因此操作对象时,实际操作对象的引用。 JavaScript 中的 Object、Array、Function、RegExp、Date是引用类型。
示例:
1 | var a = 1 |
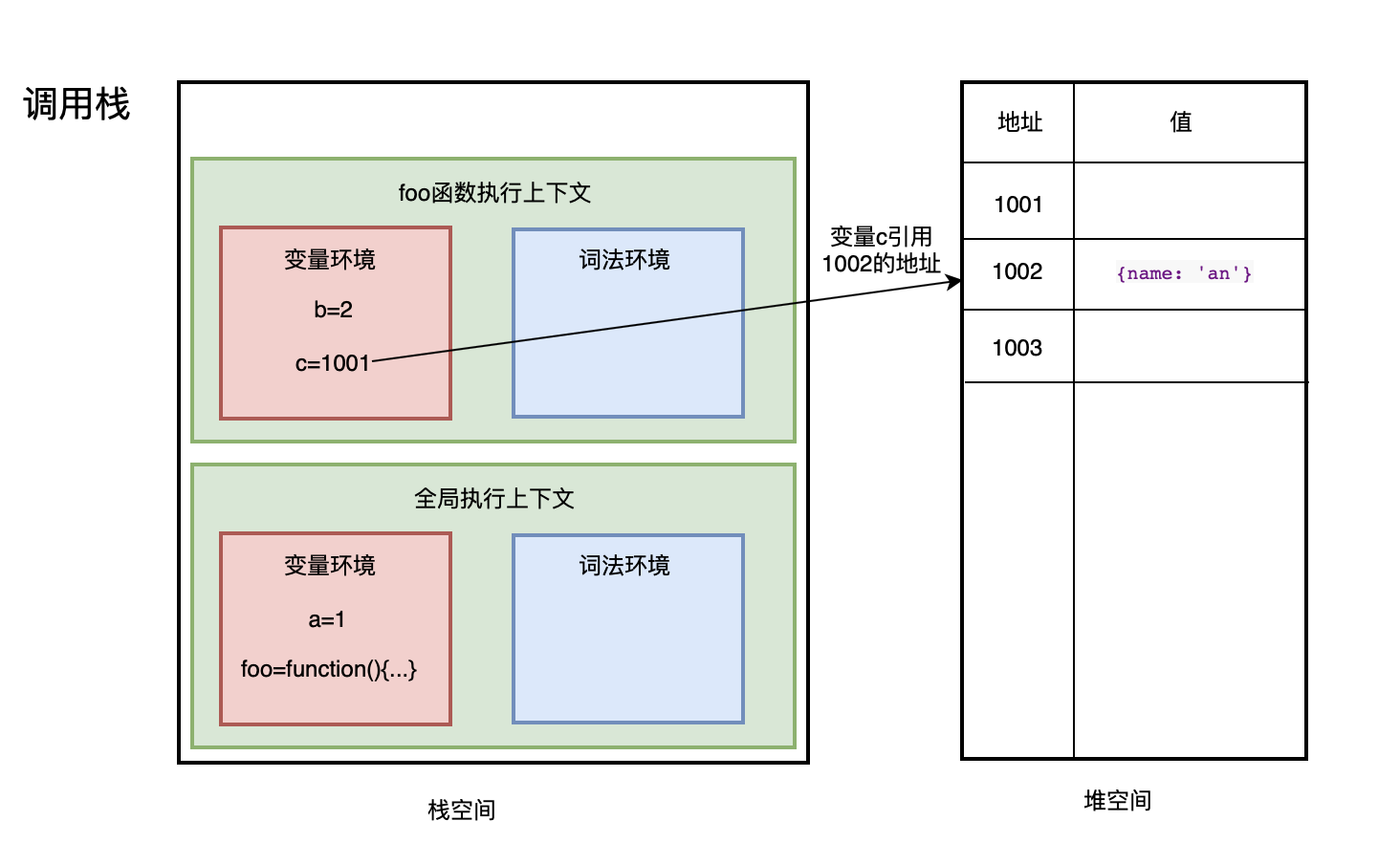
当我们要访问堆内存中的引用数据类型时:
- 从栈中获取该对象的地址引用;
- 再从堆内存中取得我们需要的数据;
- 复制基本类型
1 | let a = 20; |

在栈内存中的数据发生复制行为时,系统会自动为新的变量分配一个新值,最后这些变量都是 相互独立,互不影响的。
- 复制引用类型
1 | let a = { x: 10, y: 20 } |
引用类型的复制,同样为新的变量 b 分配一个新的值,保存在栈内存中,不同的是,这个值仅仅是引用类型的一个地址指针。
他们两个指向同一个堆内存空间,在堆内存中访问到的具体对象实际上是同一个。
因此改变 b.x 时,a.x 也发生了变化,这就是引用类型的特性。

- 总结
| 栈内存 | 堆内存 |
|---|---|
| 存储基础数据类型 | 存储引用数据类型 |
| 按值访问 | 按引用访问 |
| 存储的值大小固定 | 存储的值大小不定,可动态调整 |
| 由系统自动分配内存空间 | 由代码进行指定分配 |
| 空间小,运行效率高 | 空间大,运行效率相对较低 |
| 先进后出,后进先出 | 无序存储,可根据引用直接获取 |
浅拷贝 与 深拷贝
上面讲的引用类型的复制就是浅拷贝,复制得到的访问地址都指向同一个内存空间。所以修改了其中一个的值,另外一个也跟着改变了。
深拷贝:复制得到的访问地址指向不同的内存空间,互不相干。所以修改其中一个值,另外一个不会改变。
浅拷贝的优势在于性能出色,但是并不能都满足日常需求,很多时候我们需要改变拷贝数组的时候,原数组不受影响,这时候就需要用到深拷贝了。
- 一个通用深拷贝的实现
主要思想:- 通过判断拷贝对象的类型,如果是基本类型,直接赋值,如果是引用类型(array/object/function),则进入核心步骤
- 深拷贝的实现最重要的是处理
循环引用的问题,以下用WeakMap的方式阻止循环引用:1
2
3
4
5// 阻止循环引用
if (cache.has(target)) {
return cache.get(target);
}
cache.set(target, copy);
完整实现代码如下:
1 |
|
垃圾回收
JavaScript 中的垃圾数据都是由垃圾回收器自动回收的,不需要手动释放。
回收栈空间
在 JavaScript 执行代码时,主线程上会存在 ESP 指针,用来指向调用栈中当前正在执行的上下文。
当 foo 函数执行完成后,ESP 向下指向全局执行上下文,foo 函数执行上下文就变成无效的,当有新的执行上下文进来时,可以直接覆盖这块内存空间。
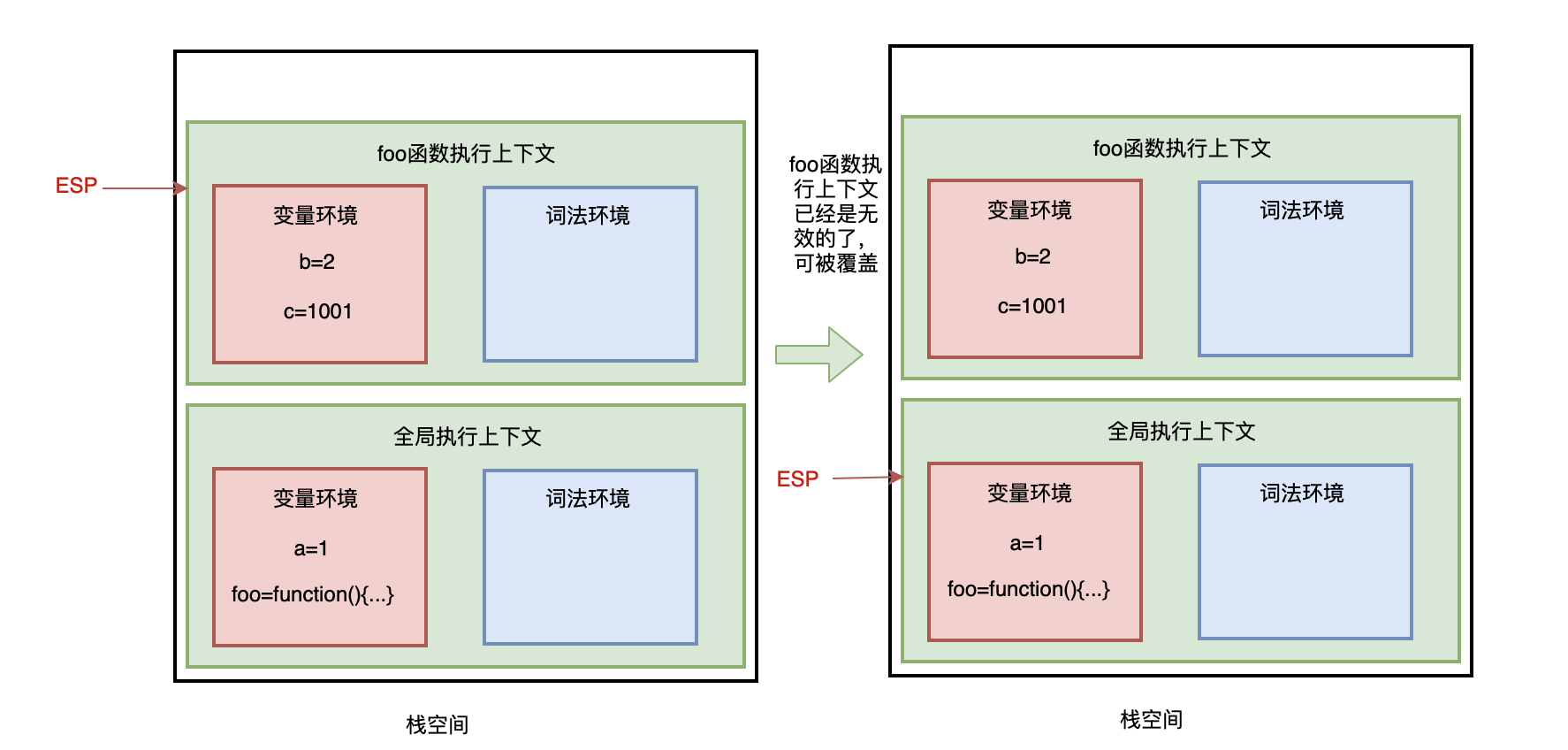
JavaScript 引擎通过向下移动 ESP 指针来销毁存放在栈空间中的执行上下文。
回收堆空间
V8 中把堆分成新生代与老生代两个区域:
- 新生代:用来存放生存周期较短的小对象,一般只支持1~8M的容量
- 老生代:用来存放生存周期较长的对象或大对象
V8 对这两块区域使用了不同的回收器:
- 新生代使用副垃圾回收器
- 老生代使用主垃圾回收器
副垃圾回收器:
采用 Scavenge 算法及对象晋升策略来进行垃圾回收
所谓 Scavenge 算法,即把新生代空间对半划分为两个区域,一半是对象区域,一半是空闲区域。
新加入的对象都加入对象区域,当对象区满的时候,就执行一次垃圾回收,执行流程如下:
- 标记:首先要对区域内的对象进行标记(活动对象、非活动对象)
- 垃圾清理:将对象区的活动对象复制到空闲区域,并进行有序的排列,当复制完成后,对象区域与空闲区域进行翻转,
空闲区域晋升为对象区域,对象区域为空闲区域
翻转后,对象区域是没有碎片的,此时不需要进行内存整理。
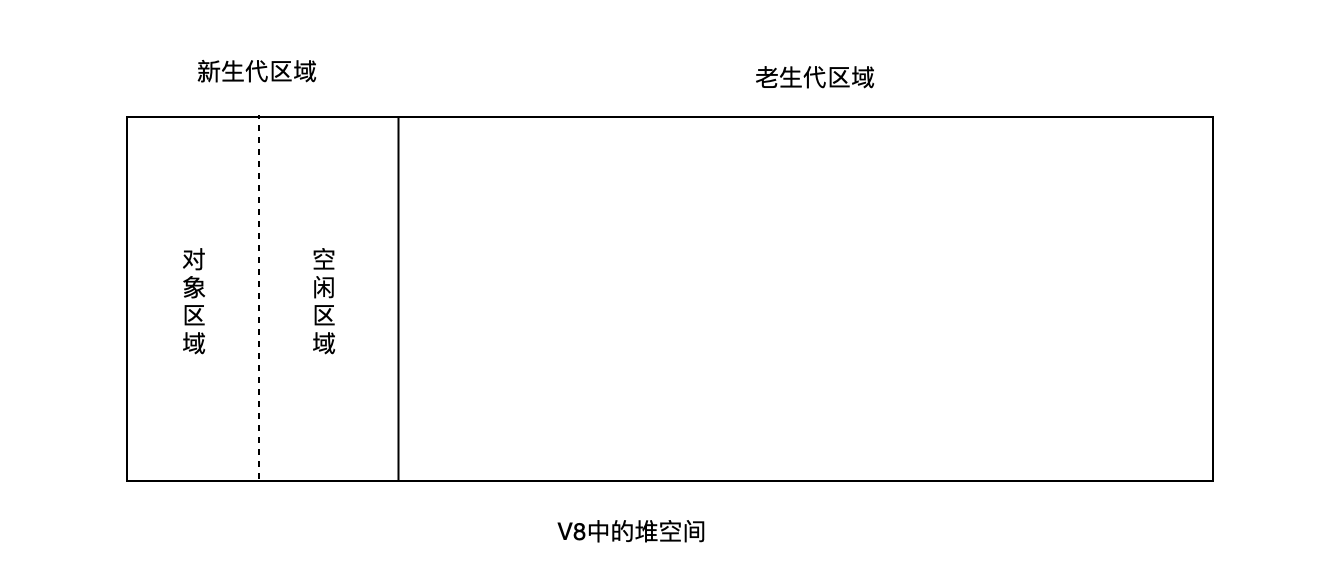
所谓对象晋升策略,因为新生代区域很小的,一般1~8M的容量,所以它很容易满,所以,JavaScript 引擎采用对象晋升策略来处理: 即只要对象经过 两次 垃圾回收之后依然继续存活,就会被晋升到老生代区域中。
主垃圾回收器:
老生代区域里有两块对象:
- 从新生代晋升来的存活时间久的对象
- 大对象(直接分配到老生代)
V8 中主垃圾回收器主要采用标记-清除法进行垃圾回收。
主要流程如下:
- 标记:遍历调用栈,看老生代区域堆中的对象是否被引用,被引用的对象标记为
活动对象,没有被引用的对象(待清理)标记为垃圾数据。 - 垃圾清理:将所有垃圾数据清理掉
- 内存整理:标记-整理策略,将活动对象整理到一起
增量标记:
V8 浏览器会自动执行垃圾回收,但由于 垃圾回收 也是运行在主线程上的,一旦执行垃圾回收,就要打断 JavaScript 的运行,可能会造成页面的卡顿,影响用户体验,所以 V8 采用增量 标记算法回收:
即把垃圾回收拆成一个个小任务,穿插在 JavaScript 中执行。
总结
本文内容回顾:
栈与堆的定义与对比:
- 栈:线性结构,LIFO
- 堆:非线性结构,杂乱无章,方便存储与开辟内存空间
以及JS的运行机制:
- 调用栈
- 任务队列
调用栈
- 调用栈是 JavaScript 用来管理函数执行上下文的一种数据结构,它记录了当前函数执行的位置,哪个函数正在被执行
栈内存与堆内存
- 栈内存: 基本类型(Boolean、Null、Undefined、Number、String、Symbol)
- 堆内存: 引用类型(Object、Array、Function、RegExp、Date)
浅拷贝 与 深拷贝
垃圾回收
- 回收栈空间:
- JavaScript 引擎通过向下移动 ESP 指针来销毁存放在栈空间中的执行上下文。
- 回收堆空间:
- 副垃圾回收器 与 主垃圾回收器 的区别
- 增量标记: 解决阻塞主进程问题
- 回收栈空间:
